HTTP (Hypertext Transfer Protocol-超文本传输协议)入门。
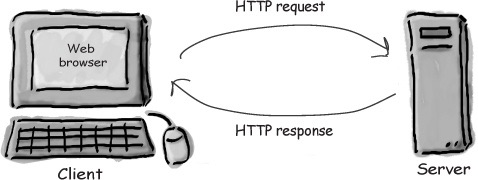
什么是 HTTP
身为一个 Web 工程师,最需要熟悉的就是应用层的 HTTP 协议了,这是目前最广为流行的应用层协议。
HTTP,是指由客户端发送 HTTP Request (请求)到服务器端,然后服务器端返回 HTTP Response (回复)。HTTP 一定是先从客户端开始,服务器端不能直接发送信息给客户端。(Hypertext(超文本) 意思是拥有超链接(一点就跳去另一个网页)能力的文件)
举个具体例子:
当你在浏览器输入 http://51world.win 时,浏览器就会将以下的信息装进 TCP/IP 数据包内,然后通过 因特网 传到服务器:
1 | # 这个 Request 只有 Header,没有 Payload |
服务器在接收到以上的信息后,会回传以下的 HTTP Response 给浏览器:
1 | # 这个 Response 的前两行是 Header,空一行之后是 Payload,也就是 HTML 内容 |
Tips
因特网(Internet) 和 Web(万维网) 的技术差别是指:用TCP/IP技术的叫做因特网,用HTTP技术的叫做万维网。
万维网当然也是因特网的一种,但不是每个因特网的应用都使用 HTTP 协议,例如 email 邮件系统使用SMTP协议。
curl 指令
curl 指令可以在命令行中发送 HTTP Request:
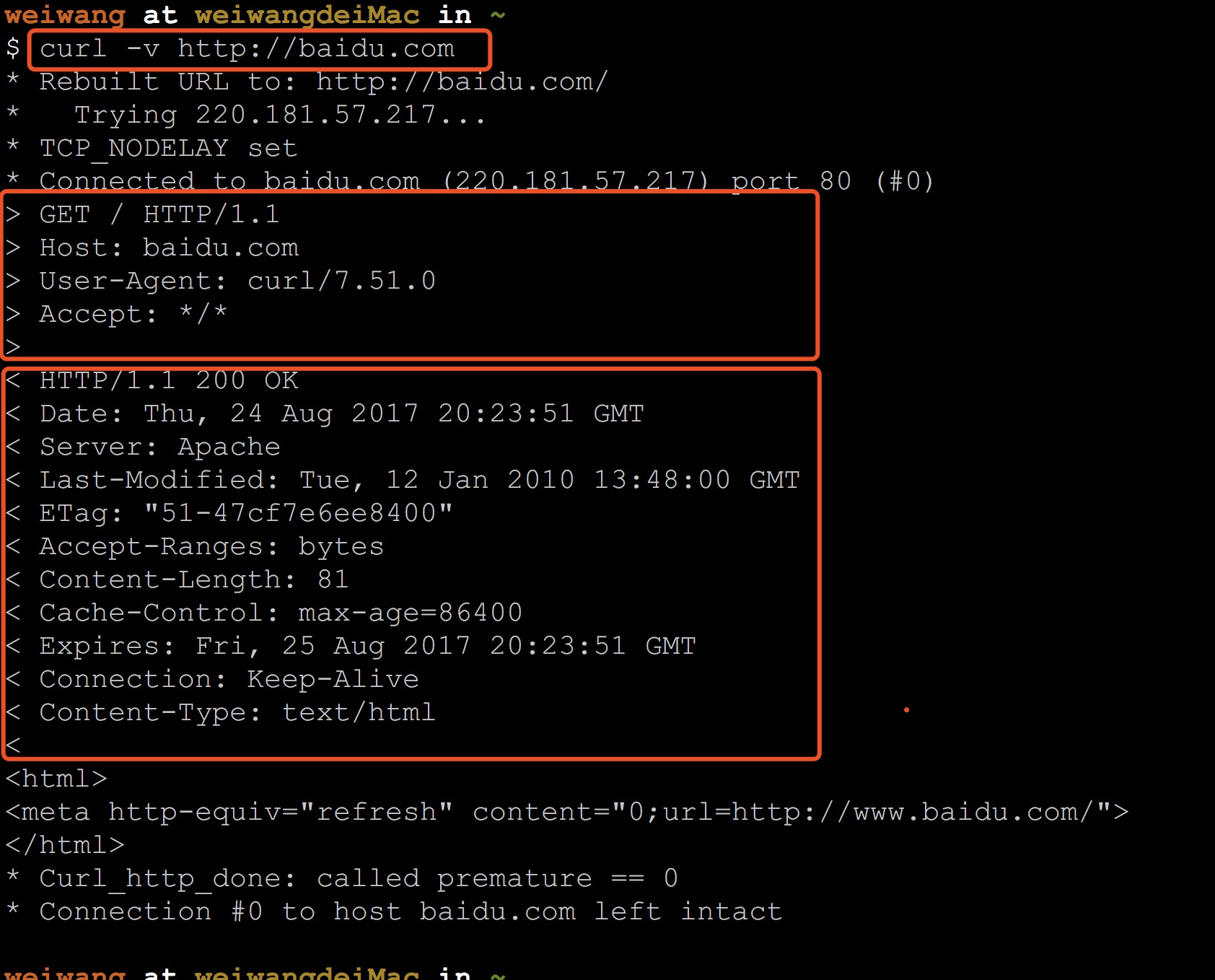
其中 > 的部分就是完整的 Request 数据包,< 的部分就是完整的 Response 数据包。
要更人性化的显示,可以用 httpie 工具。(可用 brew install httpie 安装)
浏览器的 HTTP 工具
和 TCP/IP 二进制的 Header 不同,HTTP Header 是可以阅读的文字。
Inspector
使用 Google Chrome 的 Inspector 可以观察 HTTP Networking 的情形:
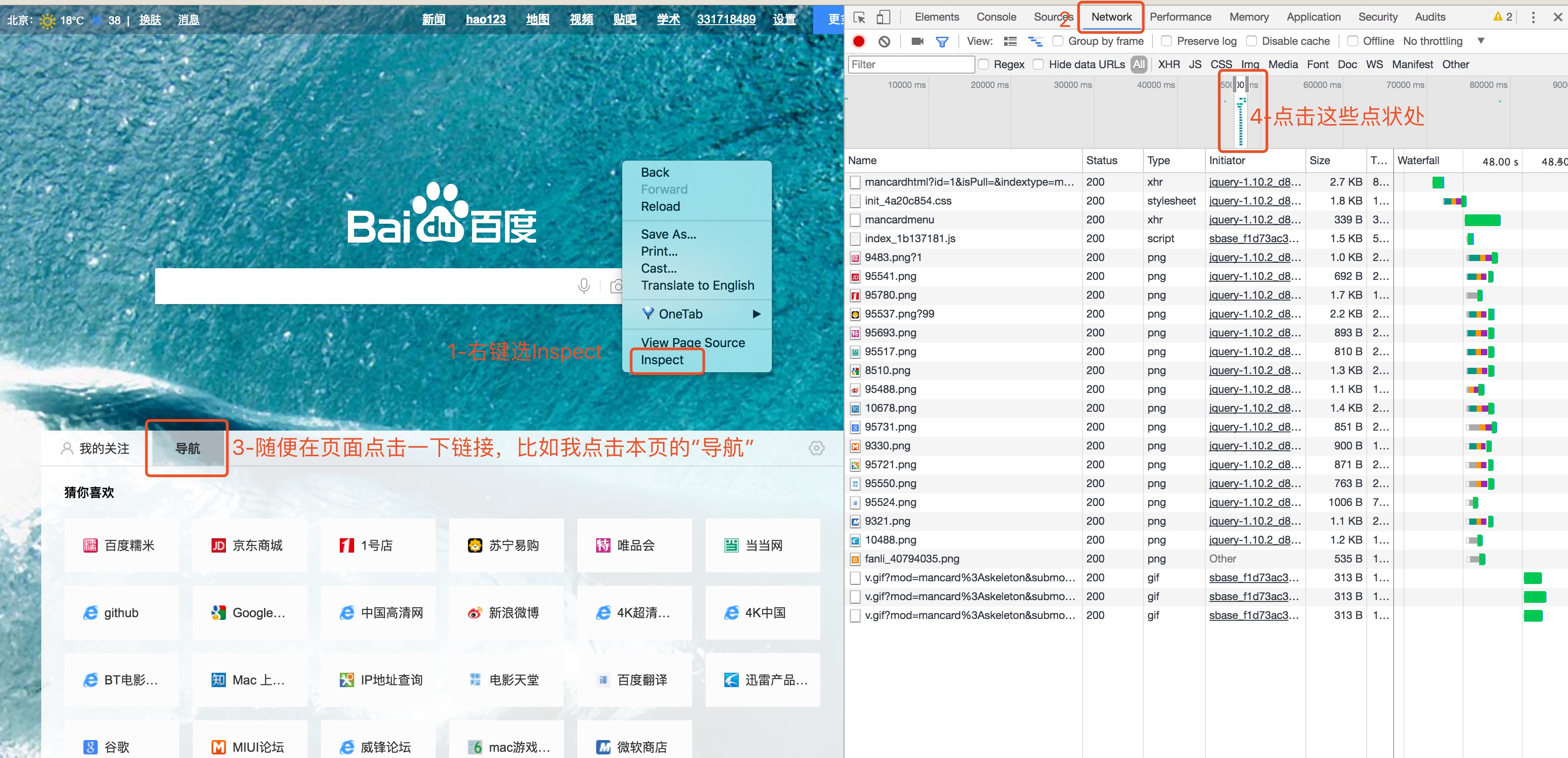
每一行就是一个 HTTP Request。你会发现浏览器要完整加载一个网页,必须要发送非常多的 Request。我们继续观察:
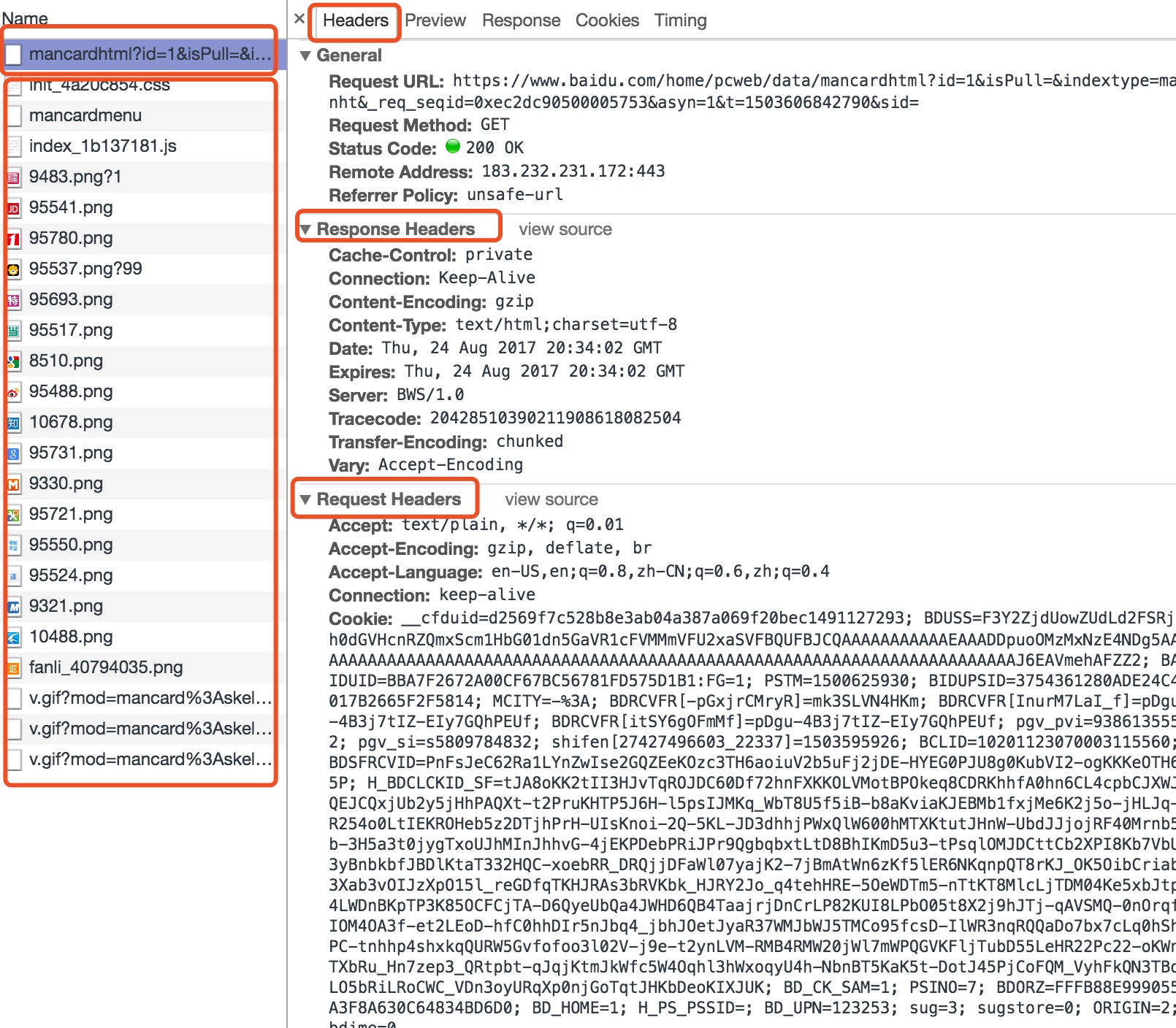
第一个 Request 拿到 HTML,接着浏览器会解析 HTML 内容,找出还需要哪些 CSS/JavaScript 和图片等资源,然后再发送 HTTP Request 去抓取这些资源。
可以进一步观察每一个 Request 的细节,包括 Request Header 和 Response Header …
Extension
介绍一个 Google Chrome 扩展插件 Postman。它是一个万用的表单工具,可以让我们在浏览器中发送自定义的 HTTP Request。
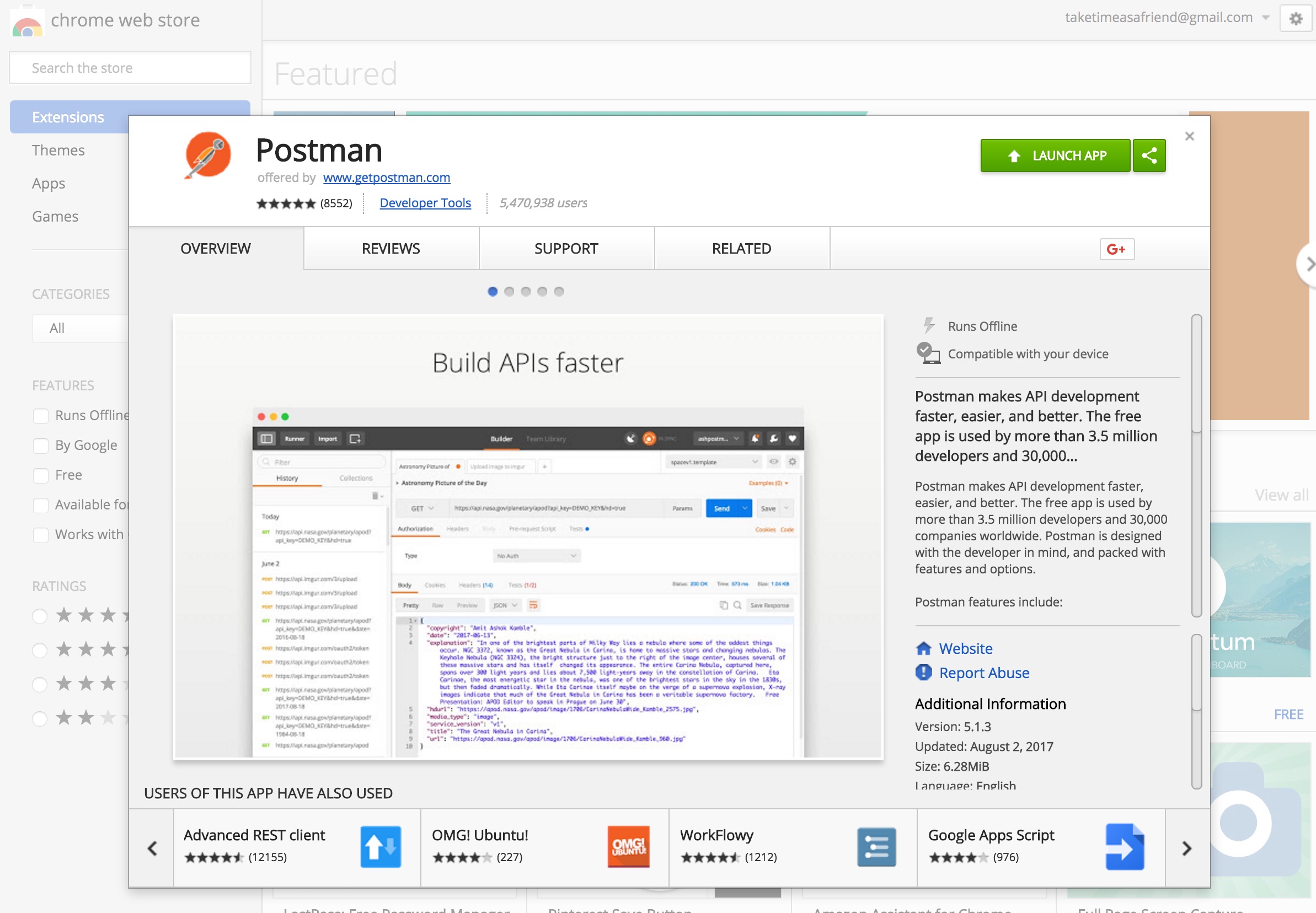
通过这个工具,我们可以指定 URL 地址、HTTP 方法和要传递的参数。
HTTP 数据包详解
HTTP Request
一个 HTTP Request 包括:
- HTTP 方法(Method)
- 网址(包括 URL + parameters)
- HTTP 首部 (Header)
- 信息内容 (Message Body)(GET 方法没有这个部分)
举例来说:
1 | > GET / HTTP/1.1 # 第一个是 HTTP 方法;HTTP 目前通行的版本是 HTTP 1.1 |
Host 指域名。在同一个 IP 对应的服务器上可能同时有多个网站(TCP/IP 首部上的 IP 是一样的数字,抵达服务器后也用一样的 Port (HTTP 用80、HTTPS 用443)),通过 Host 来区分。
User-Agent 是用户使用的软件。由于历史因素,这些字符串都很丑。另外,User-Agent 不代表客户端真的用这个软件,可自行修改。
Accept 指希望服务器回传的格式。
*/*是都可以的意思。像 Chrome 浏览器的 GET 操作默认会用text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,表示第一优先是text/html格式。如果 HTML 表单用 POST 送出,浏览器则会用
application/x-www-form-urlencoded或form-data格式,详见 四种常见的 POST 提交数据方式。信息内容(Message Body):GET 没有信息内容,要用
POST/PATCH/PUT/DELETE才会有。另外,因为浏览器的网址有长度限制,若 HTTP Request 带很多数据时就不能用 GET。所以 HTML 表单的送出默认是用 POST。
HTTP 方法 常见有以下几种:
-GET: 用来读取数据 (安全(Safe) 且 幂等(Idempotent))。情形:在浏览器中输入网址;点击网页中的超连结。
-POST: 用来新增数据或执行某个操作 (不安全(Non-safe) 且 不幂等(non-idempotent))。情形:网页中的 form 表单,默认用 POST 送出。
-PUT: 用来置换数据 (不安全 但 幂等)
-PATCH: 用来修改数据 (不安全 且 不幂等)
-DELETE: 用来删除数据 (不安全 但 幂等)
在 Ajax 中,我们可以用 JavaScript 自行指定要用哪一种 HTTP 方法。安全 :这个操作不会修改服务器数据。
但这只是语意的意思,不代表服务器的实作。如 GET 某个网页,服务器还是可以实作浏览量(Page view)功能,每次有人浏览就在数据库+1。但是我们并不会因此就改成用 POST 或 PATCH 方法,因为从用户的立场来说,浏览网页并不预期会修改或新增数据。
幂等 :如果相同操作再执行第二遍第三遍,结果还是跟第一遍的结果一样。例如点删除第二次或是第三次,最终结果跟点完第一次是一样的,那笔数据已经被删除了。
这个特性对支持离线(offline)功能的软件比较重要,表示这个操作如果失败,是可以放心重试(retry)的。
不过浏览器默认不支持离线功能,没连上网无法浏览和操作网站。像桌面客户端或手机软件才会优先考虑离线场景。
另外,还有一些细节要注意:
互联网都会假设 GET 是可以重复读取并缓存的,而 POST 不行。因此搜索引擎只会用 GET 抓资料,像这篇文章就闹了笑话,这个人用 GET 来删除资料,造成 Google 爬虫一爬就删除了,他还以为是 Google 故意黑他…
浏览器的表单送出是 POST。如果我们在action中不redirect(也就是让浏览器去 GET 另一页),而是直接render返回,那如果用户重新刷新页面的话,浏览器会跳出以下警告:
要求用户确认是否再 POST 一次,这可能会造成重复操作(重复新增)。如果是 GET 的话,刷新就不会有这种警告了。
PUT 和 PATCH 看起来很像,在 Rails 中 PUT 和 PATCH 的确没有差别,但根据 HTTP 规格有语意上的差异,详细可以参考 HTTP Verbs: 谈 POST, PUT 和 PATCH 的应用。
HTTP Response
一个 HTTP Response 包括:
- 状态码 (Response Status)
- 首部 (Response Headers)
- 信息内容(Response Body)
举例来说:
1 | < HTTP/1.1 200 OK # HTTP/1.1 - 版本、200 - 状态码数字、OK - 状态码 |
- 状态码数字:2XX(成功,例如 200),3XX(转向,例如 301 (永久转向)、302 (暂时转向)),4XX(客户端问题: 例如 404),5XX(服务器问题: 例如 500)… 完整的 HTTP 状态码列表 看起来很多,一般不会区分这么细。对浏览器来说 200、301、302 就够了。很多状态码的设计是针对网络设备、Web API 使用,而非浏览器场景。
常见的 Request Header 有:
—Content-Type:指明信息内容格式。Response Body是没有限制格式的,如 HTML 是text/html; charset=UTF-8;在 Web API 中有时用application/json;如果是 JPG 图片则是image/jpeg。完整的内容格式列表请参考 MIME。
—Location:搭配 301 或 302 转向的时候使用。如当浏览器看到 301 状态码时,会用 Location 写的地址来做转址,浏览器会跳去 Location 指定的网址(如果是你自己写的客户端程序,看到 301 或 302 不会自动跳转)。
—Accept-Encoding: gzip, deflate, br:告诉浏览器信息内容经过压缩,请解压。现代 HTTP 服务器都有这样的功能,可以大大加速下载速度。
— 现代浏览器还支持一些增加安全性的 Header,如Strict-Transport-Security、X-Content-Type-Options: nosniff、X-XSS-Protection等,对网络安全有兴趣的请参考:HTTP Headers 的资安议题 (1)、Content-Security-Policy - HTTP Headers 的资安议题 (2)、HttpOnly - HTTP Headers 的资安议题 (3)。
— HTTP Header 还有一些是告诉浏览器和路由如何缓存、哪些信息可以缓存,例如Cache-Control、ETag和Last-Modified等,让浏览器不需要重复抓取一样的内容。有兴趣的请参考 HTTP Caching。在正式的部署中,我们也会设定静态文件(CSS/JavaScript/图片等)可以缓存,告诉浏览器可以放心地缓存这些静态文件。( Rails 的 Asset Pipeline 会将静态文件的文件名修改成根据内容加上 digest 编码(只要静态文件内容修改,文件名就会变更),那浏览器就会重新下载到最新的档案,而不怕继续用旧的缓存)
HTTP 的无状态(Stateless)特性,以及用 Cookie 做状态管理
在 HTTP 的设计中,每个 Request 之间都是独立的(和前后 Request 相比),也就是说每个 Request 必须带有完整的参数来完成操作。
那要如何识别已经登入的用户呢? 每个 Request 都要自带可以识别的信息。
如浏览器会使用 Cookies 功能。服务器透过 Response Header 的 Set-Cookie 来告诉浏览器要记住一些数据,然后浏览器会在之后的 Request Header 都带有 Cookie 这个 Header:
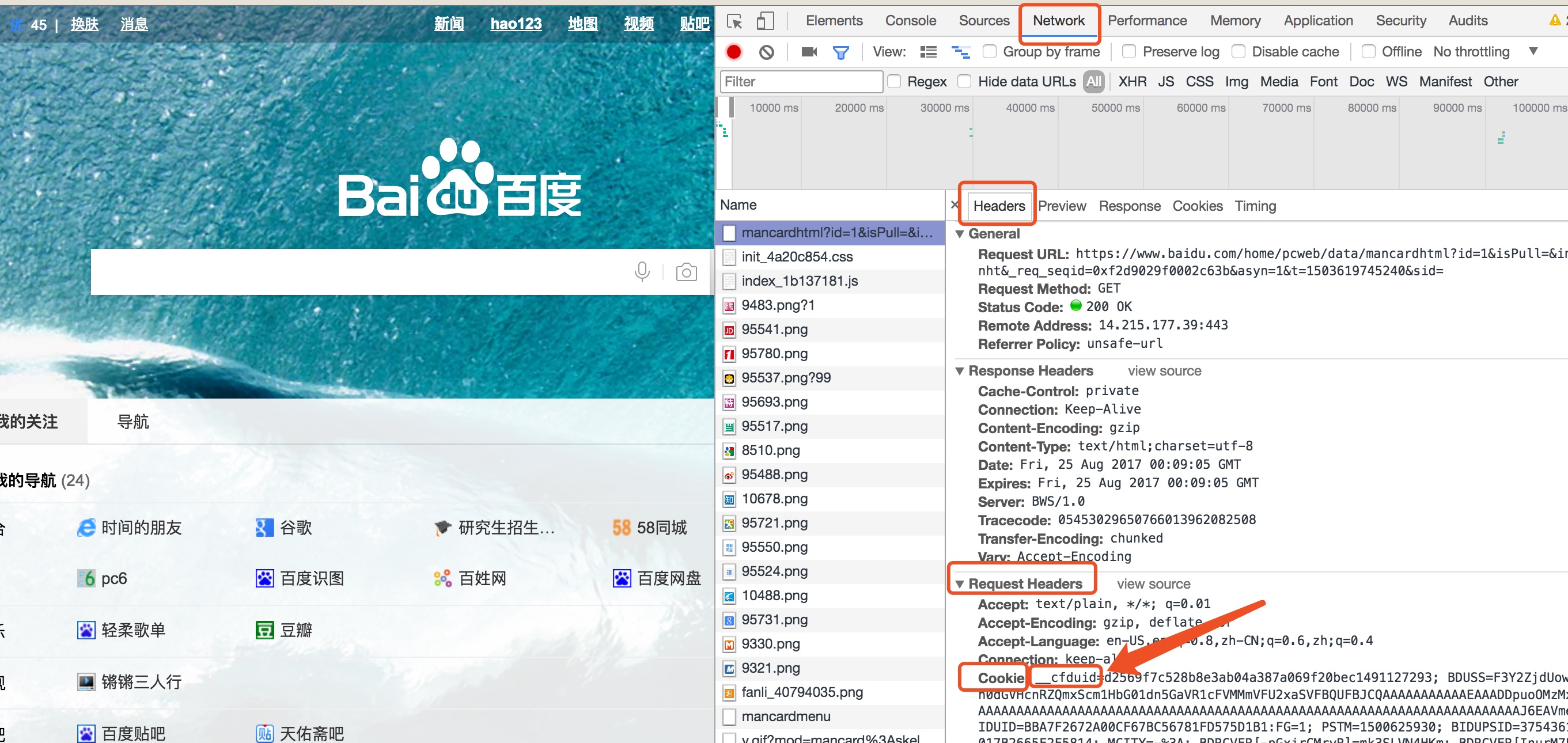
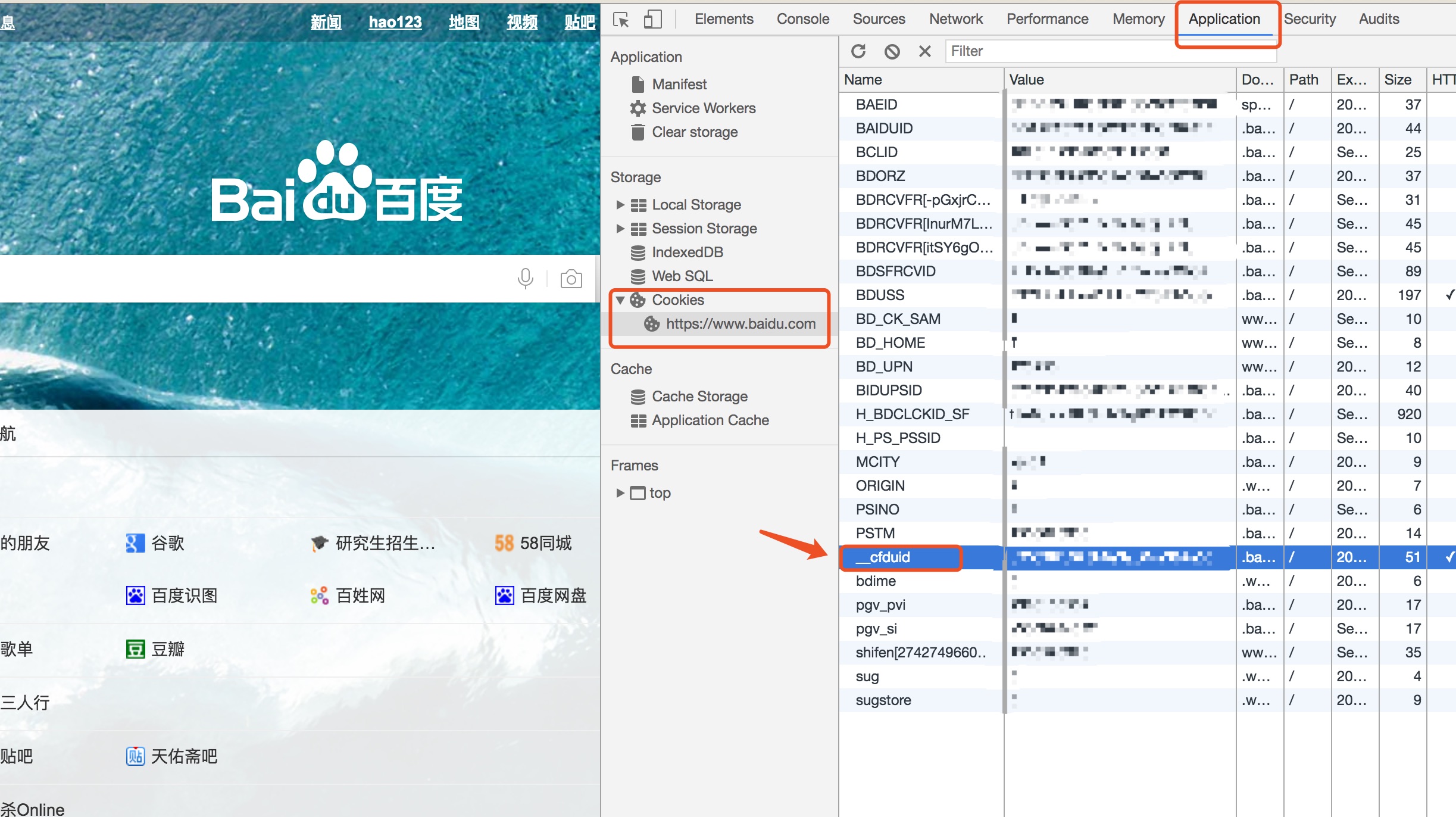
Cookie 只会向同一个域名送出,这是浏览器的安全同源政策 Same-origin policy。
截图中还看到除了 baidu 之外的 Cookie,这是因为这个网页安装有其他插件放在 HTML 上。你可以在网页上放其他域名的 JavaScript/CSS或图片。
关于 URL
让我们进一步了解浏览器中的网址 URL(Uniform Resource Locator)是什么。
以 http://www.example.com/home 举例:
- 协议: http
- 服务器主机(Host): www.example.com
- URL 路径(path): /home
- Port 号码:http 默认是 80,https 默认是 443。可以自己决定,如 http://www.example.com:3000
Query Strings/Parameters: 可用来额外传递一些参数给服务器,如 http://www.example.com?search=ruby&results=10 ,其中:
?: 保留符号,query string 的开头&: 保留符号,分隔 Parameter Name/Value,如 search=ruby 和 results=10- GET 或 POST 都可以用 Query Strings 来传递参数,但 GET 比较常见(因为 GET Request 也只能用这种方式传参数给服务器 (GET 没有 body))
但是用 Query String 有一些限制:
- 有长度限制 (因为 URL 长度有限制,太长会被截掉)。因此如果参数真的很多,有时候就算是查询,也会改用 POST 做(进阶查询功能,参数多到 GET 的网址放不下)
- 不适合传敏感信息。例如帐号密码或信用卡号码等,因为放网址太明显,用户甚至可以加入书签等。
- 空白和特殊字符必须做
encoded(当作网址的参数都必须要经过编码,这有一套规则(URL Encoding),如:- 空白变成
%20 !变成%21+变成%2B#变成%23- 其他还有
/?:@&等
- 空白变成
这就是为什么有时候网址很长很丑的原因。中文字也需要经过编码 (但现代浏览器会自动做转换,所以中文字看起来可以使用,是因为浏览器帮忙处理编码了)。
HTTPS 和 HTTP/2
近年来由于上网安全意识的提升,越来越多的网站使用 HTTPS 加密链接:
没有加密的 HTTP 链接,通过监听网络封包就可知道浏览器传输的内容。如:
- 在咖啡厅上网,黑客可以通过监听无线网络,看到你上网的一举一动。
- 有些咖啡厅可以在网页中植入广告,很容易修改网页内容。
推荐阅读:
HTTP/2 是 2015 年制定的最新标准,语意和功能都与 HTTP 1.1 是相容的,主要是改善加载网页的效能,详细请参考《更快更安全: 每个网站都应该升级到 HTTP/2》 。
总结
我们总结下一开始的问题:当我们在浏览器输入一个网址到显示出网页,背后发生的事情:
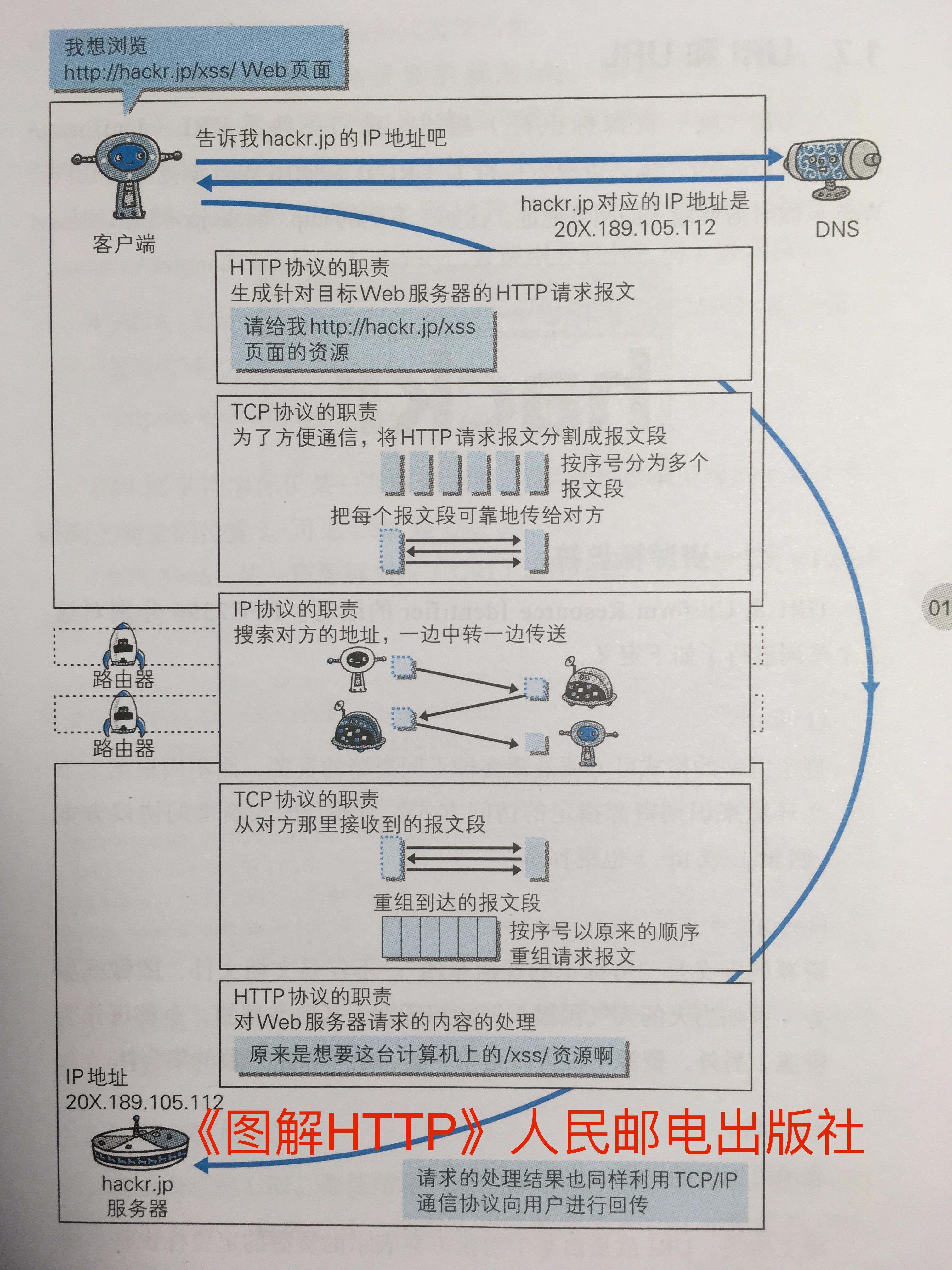
解说:
- 在网址列输入网址,或是点网页上的超链接
- 浏览器解析这个 URL 找出 protocol(协议)、host、port 和 path
- 如果是 HTTP,则组出 HTTP request 数据包
- 查询 DNS, 用 host 找出对应的 IP,组出 IP 数据包
- 组出 TCP 封包并打开一个 TCP connection 到上述 IP 和 Port
- 送出 HTTP Request 数据包
- Web 服务器(如 Nginx)接收到 HTTP Request 封包后,解析其中的内容(特别是其中的 path)来决定如何回应:
- 如果是静态内容,也就是 HTTP Response 不会根据不同用户、不同时间等任何因素而改变,例如图片、影片、CSS、JavaScript 等。那么 Web 服务器会直接将该档案回传给浏览器。
- 如果是动态内容,也就是会根据不同登陆的用户、时间等参数来回传不同内容,那么 Nginx 会将 HTTP Request 交给应用程序处理,如 PHP、Ruby、Python、Node.js、Java 等程序,由该程序动态地根据不同参数和条件,搭配数据库来取出资料,然后组合出 HTML 网页,包成 HTTP Response 经由 Nginx 回传给浏览器。
- 浏览器接收到这个 HTTP Response,开始解析这份 HTML 网页成为 Document Object Model (DOM - 一种树状的资料结构来对应 HTML 的标签节点)
- 浏览器会依序检查 HTML 源代码中,需要下载的资源网址 URL,如 CSS、图片、JavaScript 等,再发 HTTP Request 请求下载回来 (依照上述步骤 2 到 9 )
- 如果下载到 CSS 样式表,就会去装饰对应的 DOM 节点。
- 如果下载到 JavaScript ,则会执行它。浏览器上的 JavaScript 程序可以操作 DOM 节点,通常会用 jQuery 来做,来达到一些网页动态特效。
- 直到所有资源都下载完毕,浏览器执行完 CSS 和 JavaScript,才算大功告成完成 Page Load。如果你又点击网页上的超连结,则又回到步骤 1 …
拓展阅读
网络概论(一) :网络 概念初识。
网络概论(二) :DNS 原理入门。
网络概论(三) :HTTP (Hypertext Transfer Protocol-超文本传输协议)入门。


